本系列的文章将会对一些晦涩难懂的基本概念进行解释。文章侧重点在于使用通俗易懂,简明扼要的语言对这些概念进行说明。这么做的主要目标有两个:①加深对所解释的概念的理解;②提高语言组织,逻辑组织能力

1.机器学习
模型
机器学习官方定义呢是通过算法实现机器在某方面的表现的过程叫做机器学习。这个定义显然很好,很准确,但是却对初学者来说是非常非常没有意义的。
首先我们从一个最直观的角度来理解。相比你们也听说过,机器学习呢最终的目的就是为了预测。规范一点说就是通过从一堆数据中总结规律,我们可以对未知的情况发展做出预测。根据预测类型的不同呢,机器学习可以简单的分为分类问题和回归问题。而根据训练数据是否有标签可以分为有监督和无监督的训练。不同类型的问题呢,将会由不同的方案进行处理,但是我们需要注意的一点是:无论什么类型的问题,其解决的方案只会从两个大方向出发:生成式和判别式模型。
我们举一个简单的例子:红酒和白酒的判别。想象一下这样的场景:假如说你是一名鉴酒师。你的工作呢很简单,就是给你一瓶酒,你观察一下,喝一口,品一下(特征提取),然后给老板说这是白酒还是红酒(预测)。括号中加粗的两个名词呢就是你干的活了,简单吧。
现在呢,主要的问题就是怎么让电脑完成这一工作,怎么让电脑和你一样优秀?那么我们就得看看你的工作中比较难模仿的地方在哪里?没错,就是预测。你是凭借什么做出的预测呢?凭借你对酒的了解!你一生阅酒无数,从酒中总结出来了规律。这里我们需要说明一下,在这个世界上鉴酒师还有很多,他们也都总结出来了自己的规律,他们有的只是认识到了最表层的规律,有的则像你一样认识到了最深刻的规律。我们大概呢是可以将这世界上的品酒师分为两种:生成式鉴酒师和判别式鉴酒师。判别式鉴酒师比较菜,他们只会一件事:判别。顾名思义,只要给一瓶酒他们就能告诉你这是什么酒。而生成式鉴酒师可就厉害了,和酒相关的所有事情他都无所不知,无所不晓。无论是判别是什么酒,还是根据酒的类别说出酒的特点他们都能应对的游刃有余。
好啦,小故事到这里就要告一段落了,我们来看看这里的数学含义都是什么。我们首先给出几个基本概念。我们的鉴酒问题呢,本质上是个分类问题,假设我们从任意一瓶酒中提取出的信息为向量$x=(x_1,x_2,…,x_T)$,该向量包含$T$个特征(特征可以理解为属性,比如说纯度、颜色、甜度等)。那么老板给你的这瓶酒假如说是$x^{now}$,现在的问题就变成了预测酒的品种$y^{now}$。
| 判别式模型经过训练之后可以获得任意一瓶酒的条件概率$p(y | x)$,有了这个公式我们只需要把特征向量$x=x^{now}$代入,就能求出来每个类别对应的概率,那么概率最高的就是模型对这瓶酒的预测类别。即 |
常见的判别式模型如下图

生成式模型经过训练之后可以获得酒和酒的品类的所有信息,也就是联合概率分布$p(x,y)$,那么这个时候要是想对问题进行预测的话就只需要利用贝叶斯公式,就可以在预测时转化成判别式模型一样的问题。(注意,在预测一个样本的归属时,$x$是固定不变的,所以分母是不变的,因此只要比较分子就可以,而分子就是生成式模型的基本公式,所以一定是已知的)
常见的生成式模型如下图

讲到这里,我们不得不额外提到另外一种模型——生成函数模型。从前面的介绍中我们可以看出,生成式模型学的东西最多,判别式模型学的东西有所减少但是仍然足够用来做分类。并且无论是生成式还是判别式在做预测的时候都是通过比较各个分类标签的概率得到的最有可能的预测结果。而生成函数模型呢,则是采用了一种更加简洁明了的方式——直接对类别的分界线建模。我们想想一下,这样建立起来的模型,不可能对酒和类别标签的分布有着深入的认识,甚至说对酒本身的概率分布也是认识不足的,它能做的就是把酒分类,仅此而已。该模型的基本形式是
训练
前面介绍了三种基本模型,可以说有了这些模型我们就能做出预测了。但是问题就在于,这些模型怎么得到?其实确定这些模型,就是指的确定这些模型的参数,而确定模型参数就是利用手头上已经有的数据总结规律,选择最适合的一套参数,而这样的过程就是模型的训练。
模型的训练过程其实并不复杂,无论是判别式、生成式还是生成函数式,都会用一个式子来表示模型。
可以说,无论是哪一种,我们采取的措施是一样的。
1.做出假设。简单来说,就是给模型一个具体的形式。比如说我们假设$y=f(x)=w_0+w_1x_1+w_2x_2+…+w_nx_n$
2.搜索假设空间,选择最优参数。想一想,我们要选择最优的参数,最简单的办法就是遍历参数空间里所有可能的组合。但是,我们也能看出这样做的代价太大。所以存在着一系列的方法能够帮助我们更快更高效的选择最适合的参数,而这些方法呢就是优化方法,包括梯度下降等各种方法。
预测
有了训练好的模型,预测问题就变得水到渠成了。我们只需要把待预测的样本输入到模型当中,就能够根据不同的预测机制对该样本的结果进行预测。这里也就不再多说了。
神经网络
神经网络,英文全称是Atificial Neural Network,即人工神经网络。这个名字起的其实是不负责任的,因为两者之间千差万别。之所以叫这个名字是因为人工神经网络从人类神经网络中借鉴了一些观点,注意只是一些。
那么我们来看神经网络模型的提出。没错,我说是模型。神经网络就是前面提到的机器学习的模型部分替换成了神经网络。那么为什么要替换呢?答案很简单,就是原来的模型太简单,只能对简单的任务进行处理,遇到复杂的任务就麻了爪了。那么什么是简单什么是复杂呢?我们来看一下第一段中提出的一个例子。$y=f(x)=w_0+w_1x_1+w_2x_2+…+w_nx_n$。这个模型简单吧,可以说是简单到爆表,这个东西在高维空间上就是一个直线作为类别的分割线。换句话说,就是我们这个模型要想奏效,那么所有的数据必须在高维度空间上是可分的。下图就是一个二维的可视化例子。从图中我们能发现这种情况太齐整啦!我们的模型就是图中的这个直线,我们调整参数的过程就是调整这条直线的位置和斜率。但是怎么调节这个东西都是直来直去,永远是条直线。
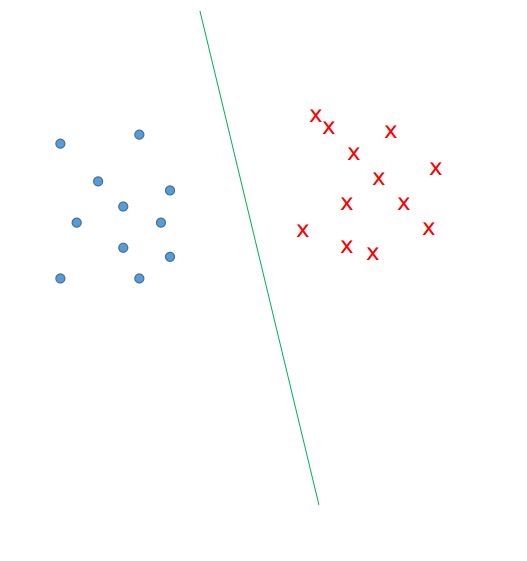
因此我们考虑给这条直线增加一点可调节性,如果说我们不仅仅是可以调节这条直线的位置和斜率,还能调整它的弧度。那这样假设空间一下子扩大了,但是能够应对的情况就更加的丰富了。而要想增加对弧度的控制就需要增加高维度的东西。模型基本形式就可以修改成$y=f(x)=w_0+w_1x_1+w_2x_2+…+w_nx_n+u_1x_1^2+u_2x_2^2+…+u_nx_n^2$。观察下面的示意图,我们发现此时的这种分布,无论用什么直线都没有办法在这个维度上进行区分了。(当然,一些降维啊什么的方法可能还是可以解决的,这里先不提)只能采用的是能够调节曲线弧度的模型。再进一步,我们发现,这个参数越多啊,我们的模型的可调节性也就越大;但是同时,参数越多,训练的难度也就越大,这是一个需要平衡的问题,这也是后话了,在此不表。总结一下,在一定程度上增加特征的高阶到模型中,有助于增加模型的有效性。
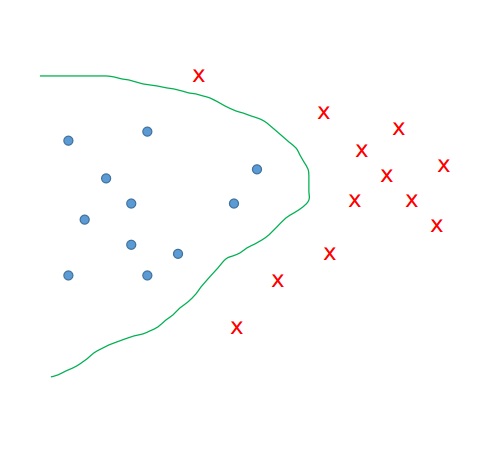
故事讲到这里,我们的神经网络就要隆重出场了。我们要知道,如果想要增加高阶的特征,可以手动的去设计,想怎么增加就怎么增加。但是也有一种比较好的增加方式,就是使用神经网络增加高阶的特征。神经网络中层的概念就是对前面的输入进行变化,这样的变换可以是线性的也可以是非线性的。其中非线性的变换呢就可以看做是增加了对弧度的控制等等。
深度学习
深度学习,一言以蔽之,就是多层的神经网络。其产生的主要原因就是人们在研究的过程中,发现使用多层的神经网络将会产生意外的好的效果。
自然语言处理
自然语言处理,是人工智能领域的一个重要的研究方向。简单来说就是想要让计算机理解人类的语言。这样一句话说出来,其实立马就有两个问题:什么是人类的语言?怎么才叫理解了人类的语言?任何一篇NLP领域的论文,其实都是在回答这样两个问题。
首先第一个问题,什么是人类的语言?这个问题不用说,你也最起码知道人类的语言是及其复杂的。形式多样,演变迅速等等特点使得人类的语言这一概念变得非常难以定义。但是有一点是没有错的,即语言是一个有多种基本规则构成的复杂的复合体。因此,所有的论文都是针对语言的某一个方面,做出一个基本假设,然后进行建模和分析。这样的假设包括“单词的含义可以从不同文章中出现的频率所确定”、“文章的含义可以从文章中单词的分布确定”、“翻译是根据原句的内容结合知识进行的解码过程”等等,这些假设有的已经过时,有的仍然炙手可热。
第二个问题,什么叫理解?正如前面所提到的,任何一篇论文都是从语言的而某一个方面出发进行研究。那么对应的理解这么一个概念就是完成不同的任务,比如预测下一个词能够预测的比较准;文章分类能够分的比较好等等。同时,我们需要知道,这些子任务整体都结合起来,完成的都比较好才能叫自然语言处理这个大任务我们已经完成了。
词向量(Embeddings)
词向量呢,简单来说就是使用一个向量来表示一个单词。其基本假设呢,是说任何一个单词都是在空间中对应了一个一个点。
我曾经在另外一篇文章中花了大力气介绍了一篇综述类的论文。在这里我也不想多费口舌了。词向量的发展主要是经历了“one-hot->document-based->hand-crafted feature vectors->word Embeddings->contextualized word Embeddings”这样一个过程。
指代消歧(Coreference Resolution)
指代消歧指的是确定文章中的两个名词短语是否指代的是同一个人、物、事等。其基本假设是:在一篇文章中,对同一个东西的指代可能有多种多样的形式,这些指代呈现出聚类的特征。举个例子来说,”张雪迎在电影狗13中表现很好。我很喜欢她的表演。”请问这里的她指的是谁?这就是指代消歧需要解决的问题。
指代消歧的基本解法有:Mention-Pair,Mention-Rank,Mention-Tree,Entity-Mention等。一个个的介绍,首先是Mention-Pair.这是目前研究最多的一种方案,其基本假设就是我们不去考虑这是个聚类的问题,我们只需要考虑一下从所有的Mention中拿出一对,判断这一对有没有是不是指代的同一个东西就好啦。这个问题就变成了分类问题。
Mention-Rank呢,就是从所有的Mention中选择一个,然后给剩下所有的Mention按照是否是指代同一个东西进行排序。这个问题就变成了排序问题。
Mention-Tree。就是把所有聚成一堆的指代当成一棵树,那么这个问题就变成了树的解析的问题。
Mention-Entity。就是认为所有的指代都是指向一个文本中没有出现过的实体,通过学习这个实体就可以完成指代消歧。这是最合理的一种假设,但是研究的人员并不算多。
结构化预测 (Structured Prediction)
结构化的预测这个概念呢,在论文中经常出现。其本意很简单,就是我们预测的最终的结果不再是一个简单的标签啦,而是一系列的标签(序列标注)或者一颗树(依赖解析)等等。
解决这种问题呢,最简单的做法是Structured Perceptron的算法。然后呢还有图模型的算法,还有呢就是结构拆开,一个个标签的去预测。都行,具体问题具体分析吧。
文本依赖解析(Discourse Parsing)
长文本的依赖是自然语言处理研究的一个重点任务。但是本质上呢还是一个依赖解析的问题。依赖解析问题的最常见处理方式有两大类:基于转移的(Transition-Based)和基于图的(Graph-Based)。前者就是一个改进版的贪心算法,通过shift-reduce的过程,扩大贪心的范围。后者就是在途中找最大生成树。
语义表示(Semantic Representation)
语义表示在自然语言处理之中是重中之重,很多问题的效果不好就是因为没有能够很有效的表示所有的语义信息。所谓的语义表示就是使用一个向量来表示一个语义单元(词,句子,文章等等)。同一个单元使用不同的学习策略能够学习出不同的语义表示。
条件随机场模型(Contional Random Field)
线性条件随机场在自然语言处理中经常用来标注序列。条件随机场模型的解释呢主要参考是这篇博客。
一言以蔽之:线性条件随机场在标注序列时的基本原理是寻找序列所有可能的标注方案中最合理的一个,合理性是由特征函数计算的来的。
问题的关键此时就落在了特征函数上,特征函数符合以下特征:①输入为:待标注的句子$s$;当前单词的位置$i$;前一个单词的标注$l_{i-1}$;当前单词的标注$l_{i}$;②输出为0或1。这特征函数到底是什么呢,我们不妨来看几个例子。以下图中的第一个特征函数为例子,这个特征函数描述了一个很简单的事情就是:如果当前单词是以ly结尾的,并且标注给的是副词,那么这个序列标注的可能性就大一些。可以看出所谓特征函数就是规则。而我们通过训练这些规则的权重来获得最终的标注器。

当然啦,这一切要想奏效还需要两个关键东西:训练方法以及最优标注的搜索方法。训练方法是通过改写成判别式模型的概率来求的;而最优标注是通过维特比算法(实际上就是个动态规划)的算法来求解的。
贝叶斯概率论(Bayesian Statistics)
贝叶斯概率论是一个困扰了我很久的问题,因为他的很多推论都是反直觉的。经过多次反复的学习,才有了一些自己的心得体会:贝叶斯概率论的究极核心就是贝叶斯公式。而贝叶斯公式描述了根据证据,把先验概率更新为后验概率的过程。
| 细心的人可能发现啦,我这种写法并不是常见的规范写法,但是这种写法是关键所在。等式左边 $p(x | evidence)$ 被成为后验概率,等式右边 $p(x)$ 被称为先验概率,而剩下的部分 $\frac{p(evidence | x)}{p(evidence)}$ 就是证据的有效性。这样我们就明白了,事件$x$发生先验概率指的是我们对这件事情的基本认知(比如我们什么都没做的情况下假设硬币是均匀的,那么事件”抛硬币是正面”的概率就是0.5,这个概率就是先验概率);证据的有效性呢顾名思义就是某一个证据的出现对我们判断事件 $x$ 是否出现有多大的帮助(比如说有一个检测智障超级准的仪器检测出来某人是智障,那么我们本来觉得是五五开的,现在我们也没办法只能说哎呀这人怕不是真是个智障哟);后验概率呢就是我们更新之后的认知。 |
| 在这里我觉得有必要说明一下为什么 $\frac{p(evidence | x)}{p(evidence)}$ 可以用来表示证据的有效性。我们抛开这个公式想一下,怎么说明某个证据有多有效?其实很简单:如果这个证据只和事件 $x$ 一起出现,不和别的事件一起出现,或者说极少跟其他事件一起出现,那么这个证据对于判定事件 $x$ 是否发生了将会是决定性的。这样的话我们就可以使用 $\frac{p(evidence | x)*p(x)}{p(evidence)}$ 作为证据的有效性,那么这样的话贝叶斯概率公式就变成了 |
啊嘞雷,相信聪明的你已经发现这里多了一个分子上的 $p(x)$ 这才应该最合理的概率更新公式。但是呢,这太复杂,我们可以发现,这个公式和贝叶斯公式相比就是少乘了一个先验概率,而在更新事件 $x$ 的时候先验概率总是不会发生改变的,所以乘以一个乘以两个,相对大小是不会发生改变的。所以为了简便起见我们采用了一个,也就是如今的贝叶斯概率公式。
LDA(Latent Dirichlet Allocation)
LDA模型通常是用来做主题模型的,其过程可以说是超级简单的。具体的可以参考我在简书上对某一篇论文的分析。其基本思路是:一篇文章中的每一个单词都是根据多个主题生成的,这里的每一个主题都是一个单词的概率分布。我们想要的东西就是这些概率分布。首先随机为文章中的单词主题进行标注,然后扫描每一个单词,根据除当前单词以外的所有单词的分布来对当前单词进行重新标注。标注错了就更新分布。多次扫描直到收敛为止。
在这里,虽然过程中没有涉及到很复杂的概率模型,但是我觉得有必要额外的提一下这个模型和贝叶斯概率的关系。我们在前文中介绍了贝叶斯概率论就是在根据证据更新先验分布。那么我们基本想法就是,如果我们有了先验分布,只需要根据证据一次一次又一次的更新分布,最终会越来越接近最终的后验分布的形式。这里呢,有一个很关键的问题就是先验分布怎么去定义?当然啦,有人就说哇,我们就均匀分布去定义呗,还能咋地?可以,但是这样做存在一个问题,就是我们如果采用均匀分布作为先验,那么根据证据更新完一波之后,我们得到的这个概率分布是什么概率分布?假如你运气好,更新完了之后是个正太分布啦。那么下面再更新呢?我们还怎么去定义?因此我们希望是每次更新完,概率的形式都不会发生特别大的改变,只是调调参数而已。这样呢就出现了共轭先验分布的概念。这个分布就能做到你根据证据更新了之后,概率的形式不会发生特别大的改变,即先验和后验概率有着相似的形式(属于同一个概率族)。所以我们在做先验假设的时候通常就会从这些先验里选择一个,而不是随便就来。下面给出一些共轭先验分布的例子。
conjugate prior wikipedia
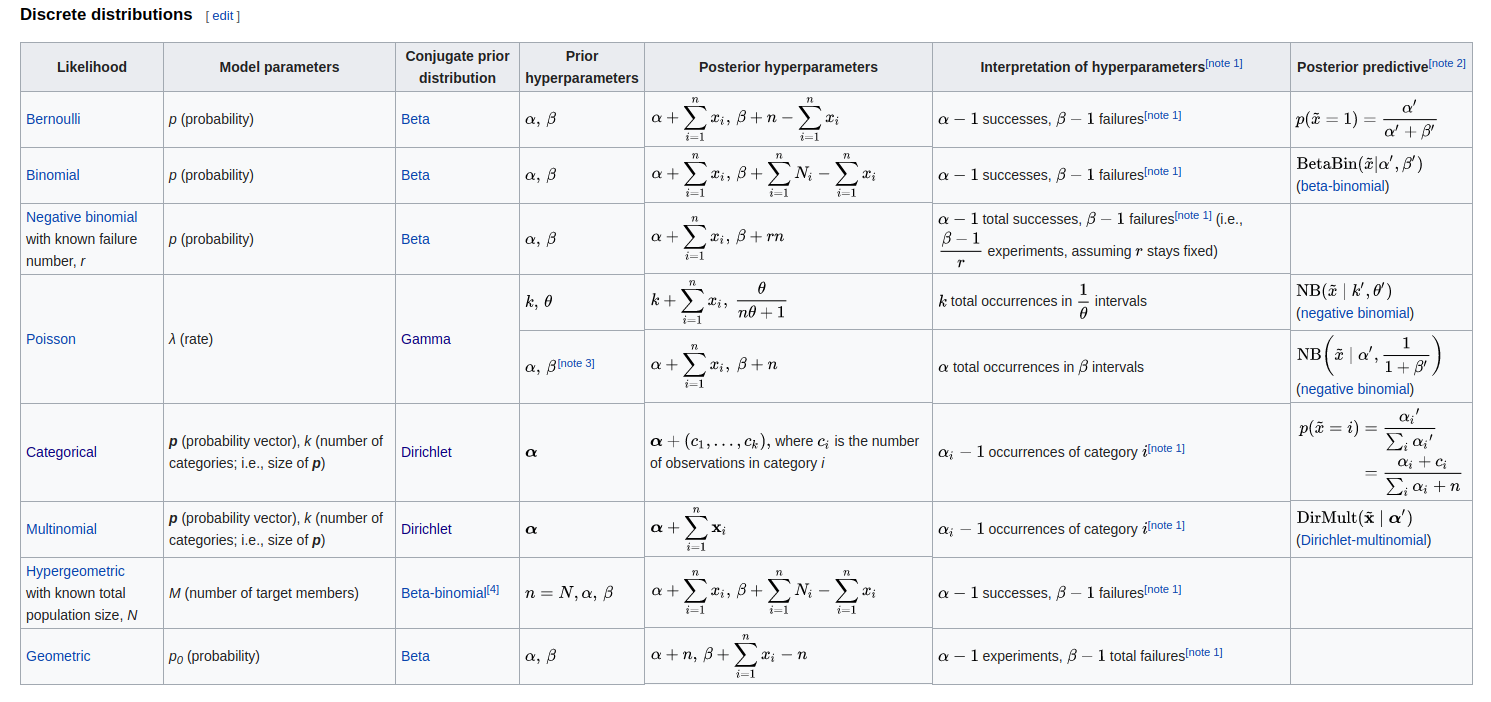
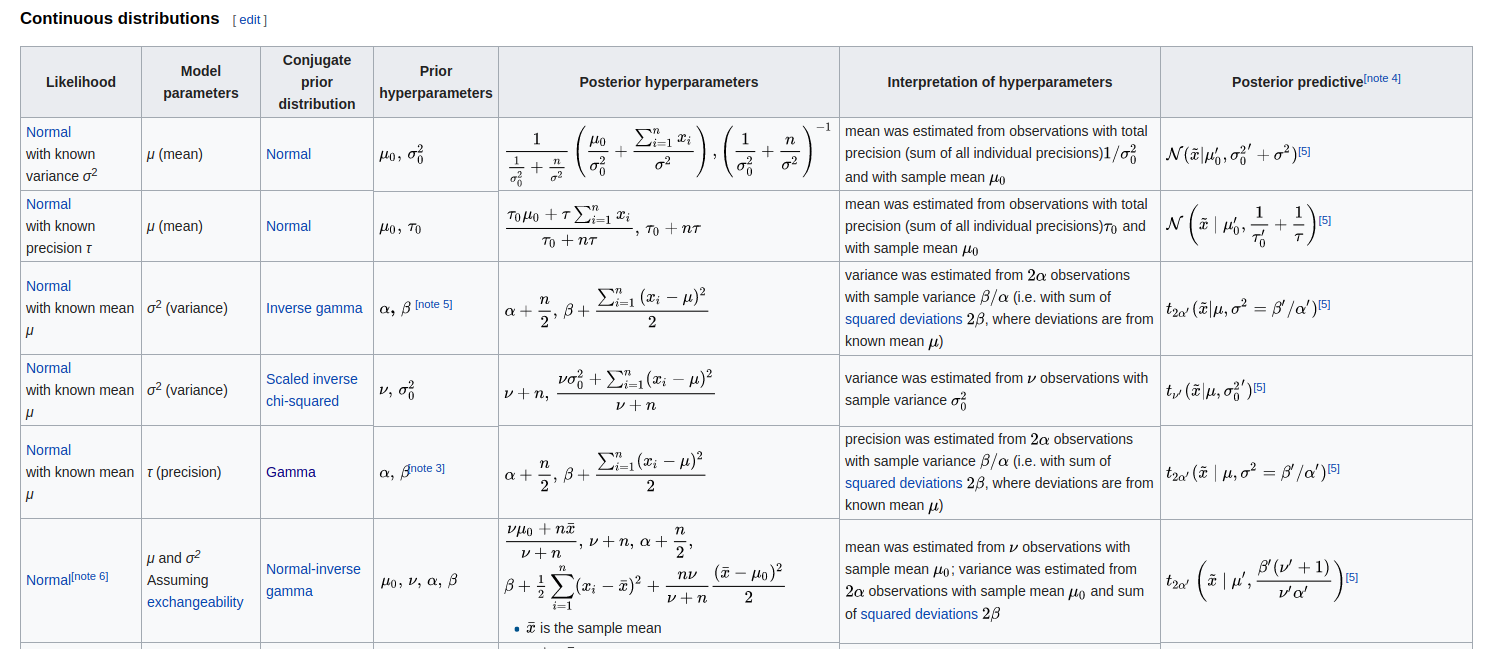
之所以要讲这么多这玩意,主要的原因就是这里我们的LDA模型最根本的原理就是选择狄利克雷分布作为先验,然后根据证据不停的更新我们的认知。
import_ops & export_ops
如果你看过Tensorflow的官网教程,并且是严格的跟着教程走的,那么我估计你也对import_ops和export_ops这样两个函数有过困惑。这两个函数的作用不难看出是把计算图中国所有的操作都导出以及导入。真正让人迷惑的是为什么要这么折腾?????
放了好久之后,终于在其他地方找到了答案。问题并不在于为什么要导入和导出,问题在于不得不这样做。想象这样一种场景,你训练了一个很棒的模型,训练效果不错,但是训练之后加载不进来啦!!原因在于你的测试的模型和原来的模型结构有点不大一样!就那么一点不一样就够你查半天的。于是你就在想,如果能够直接把这个模型从文件中加载进来不就行啦!!这样是肯定不会出错的。
理想总是美好的,现实总是残酷的。如果我们不定义测试模型,直接从数据中获取,那么压根就没有model这么个对象,我们怎么去调用他的操作?于是我们就发散思维啦,我们也许并不需要这个抓手呢,我们想要的就只是这些操作而已,那么我们在保存图的过程中把这些操作也保存下来,保存到一个集合当中,到时候我们从集合中直接获取这些操作呢?????PERFECT!!
NLP中使用卷积神经网络
卷积神经网络的基本概念我也不想多说了,之所以在这里额外的介绍一下就是因为,我们需要将图片中的概念拿到自然语言中。这是一个不太容易的过程。
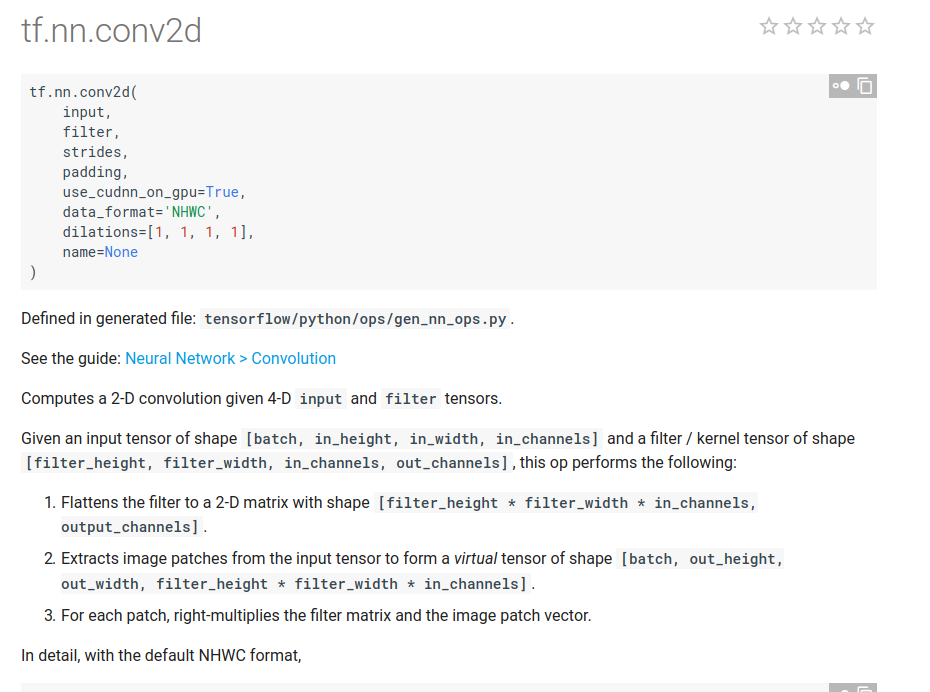
我们看一下Tensorflow官方给出的conv2d的接口介绍。其实只需要搞清楚两个基本概念就行啦,一个是输入的维度解释,一个是filter的维度解释。在这里输入是个四维的数组[batch_size,input_height,input_width,input_channel],对应到图片里非常简单[batch_size,每张图的高度,每张图的宽度,每个像素点的通道个数],我们再来看看filter.[filter_height,filter_width,input_channel,output_channel]在图片中也是很好理解的[过滤器的高度,过滤器的宽度,每个像素点的通道数,过滤器的个数]。
都不是很难理解,在这里注意两点①我们所说的宽度和高度都是说的有多少个像素点。②filter的output_channels是filter的个数,这里多说一句为什么需要起这么一个八竿子打不着的名字。其实这个名字是非常合理的,因为我们每定义一个filter完成卷积之后都会生成一个向量,这个向量再经过池化层就变成了一个数,那么再把每个filter生成的数拼接起来就成了一个维度为filter的个数的向量了。
下面就要说一说自然语言处理里面的内容啦。怎么类比过去呢。比如说我们需要对字进行卷积的话,那么我们就可以类比每个字就是一个图片,只不过这个图片比较特殊:只包含一行像素点(每个像素点就是一个笔画)。正是有了这样的类比,所以我们在做自然语言处理的卷积的时候通常都会做一步变形,把batch的数据拉平,这是因为我们需要对一个字的所有笔画进行卷积而不是一个batch的乱七八糟的东西。
Filler-gap Movement(填坑运动?)
Filler-gap Movement是一种语言现象。常识:英文中如果是疑问句(特殊疑问句)都会改变原来句子的顺序。或者换种说法,就是词不再原来的位置待着,而是跑到了另外一个位置,就在原位置徒留一个坑。比如说句子
“What did you eat for breakfast today?”这句话就是明显的发生了语序的改变,正常的描述语序应该是:You eat __ for breakfast today.这里的下划线就是坑!因为东西跑啦,跑到前面摇身一变,野鸡变凤凰成了疑问词了!
不开玩笑啦,这是一种重要的语言现象,具体点说是能够导致语序发生改变的四种语言现象中的一种,剩下三种以后再去研究,在这里先贴出来。